Development¶
How to contribute¶
You can contribute to improve Django Dynamic Scraper in many ways:
- If you stumbled over a bug or have suggestions for an improvements or a feature addition report an issue on the GitHub page with a good description.
- If you have already fixed the bug or added the feature in the DDS code you can also make a pull request on GitHub. While I can’t assure that every request will be taken over into the DDS source I will look at each request closely and integrate it if I fell that it’s a good fit!
- Since this documentation is also available in the Github repository of DDS you can also make pull requests for documentation!
Here are some topics for which suggestions would be especially interesting:
- If you worked your way through the documentation and you were completely lost at some point, it would be helpful to know where that was.
- If there are unnecessary limitations of the Scrapy functionality in the DDS source which could be eliminated without adding complexity to the way you can use DDS that would be very interesting to know.
And finally: please let me know about how you are using Django Dynamic Scraper!
Running the test suite¶
Overview¶
Tests for DDS are organized in a separate tests Django project in the root folder of the repository.
Due to restrictions of Scrapy’s networking engine Twisted, DDS test cases directly
testing scrapers have to be run as new processes and can’t be executed sequentially via python manage.py test.
For running the tests first go to the tests directory and start a test server with:
./testserver.sh
Then you can run the test suite with:
./run_tests.sh
Note
If you are testing for DDS Django/Scrapy version compatibility: there might be 2-3 tests generally not working properly, so if just a handful of tests don’t pass have a closer look at the test output.
Django test apps¶
There are currently two Django apps containing tests. The basic app testing scraper unrelated functionality
like correct processor output or scheduling time calculations. These tests can be run on a per-file-level:
python manage.py test basic.processors_test.ProcessorsTest
The scraper app is testing scraper related functionality. Tests can either be run via shell script (see above)
or on a per-test-case level like this:
python manage.py test scraper.scraper_run_test.ScraperRunTest.test_scraper #Django 1.6+
python manage.py test scraper.ScraperRunTest.test_scraper #Django up to 1.5
Have a look at the run_tests.sh shell script for more examples!
Running ScrapyJS/Splash JS rendering tests¶
Unit tests testing ScrapyJS/Splash Javascript rendering functionality need a working ScrapyJS/Splash (docker)
installation and are therefor run separately with:
./run_js_tests.sh
Test cases are located in scraper.scraper_js_run_test.ScraperJSRunTest. Some links:
SPLASH_URL in scraper.settings.base_settings.py has to be adopted to your local installation to get this running!
Docker container can be run with:
docker run -p 5023:5023 -p 8050:8050 -p 8051:8051 -d scrapinghub/splash
Release Notes¶
Changes in version 0.13.3-beta (2021-06-25)
- Dropped Python
2.7support from support list - Updated
Pillowdependency from v5 to v6 (v6.2.1+), PR #147
Changes in version 0.13.2-beta (2019-02-15)
- Added Python
3.6and3.7(experimental) support, dropped Python3.4from support list, PR #119 - Added Scrapy
0.15support, dropped Scrapy0.14from support list, PR #120 - Removed Django
1.8,1.9,1.10from support list, PR #120 - Updated dependencies:
future0.15.x->0.17.x,Pillow3.xto5.x(Python3.6support), explicit newattrs>=17.4.0dependency (Python3.6support), PR #119 - Improved Travis CI support displaying test failure or passing on GitHub PRs, PR #117
Changes in version 0.13.1-beta (2017-11-07)
- Replaced hard-coded port
6800for scheduled scraper/checker runs with setting fromScrapyd(thanks @DeanSherwin for the PR) - Renamed internal item variables
item._dds_item_pagetoitem._dds_item_page_num, anditem._dds_item_follow_pagetoitem._dds_item_follow_page_num(eventually have a look at your custompipelines.pyfile if used there), useitem._dds_item_pagefor storing the page from the pagination
Changes in version 0.13.0-beta (2017-06-29)
- Pre-note: Due to an increasing test burden, this library might drop
Python 2.7support in the foreseable future (not decided yet, if so, probably within 6-12 month). If you haven’t already done so you might want to start upgrading your projects to run on aPython 3basis. - New, second pagination layer with
FOLLOWpagination type, building upon pull request #24 and allow for dynamic pagination by extracting an URL to follow from consequent pages (for example to follow pagination on the website to scrape). This can be combined with other pagination types (currentlyRANGE_FUNCandFREE_LIST). See the updated Pagination section for further details.
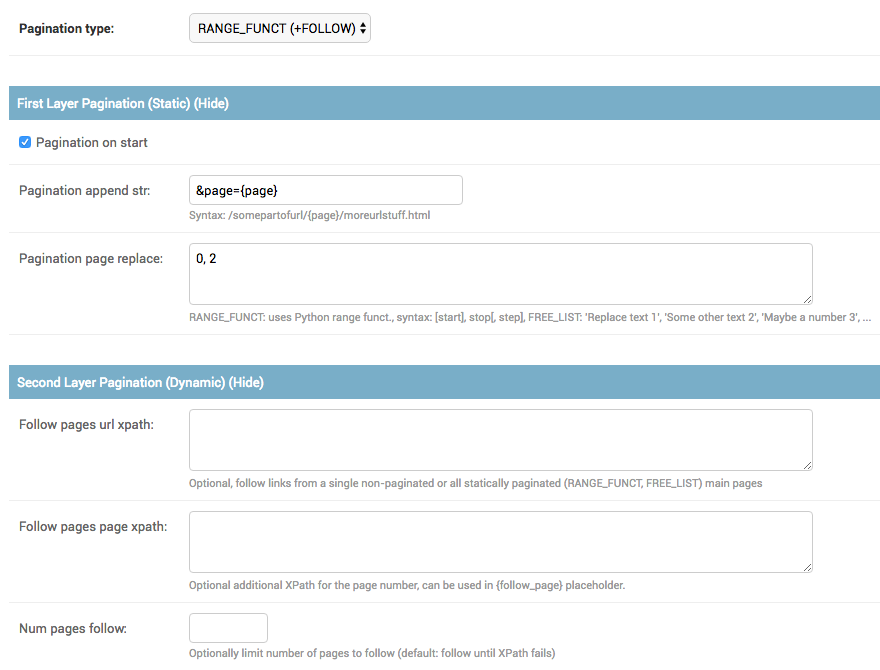
- Dropped support for
Scrapy1.1,1.2and1.3, please update yourScrapyversion to the latest1.4release version - Using
response.followfunction fromScrapy 1.4for following detail page URLs links (supports relative URLs) - New migrations
0022,0023,0024and0024,please runpython manage.py migratecommand
Added short forms for command line options:
- Allowing/enabling
{page}placeholdersforHEADERS,BODY,COOKIESfields andFORM DATAfor detail page URL requests (so you can inject the current page from the main page into the detail page URL request) - Output DDS configuration dict on
DEBUGlog level - Added a
general settingstab for thescraperform in theDjango admin - Fixed scraper elem
textarearesize for theDjango adminscraperform - Added new option
UNRESOLVEDto scraperwork_status
Changes in version 0.12.4-beta (2017-06-12)
Added possibility to select an internal work_status for a scraper to ease getting an
overview where work needs to be done, following values are possible:
WORK_STATUS_CHOICES = (
('R2', 'REVISION NEEDED (MAJOR)'),
('R1', 'REVISION NEEDED (MINOR)'),
('BR', 'BROKEN'),
('W', 'WORKING'),
('RC', 'RELEASE CANDIDATE'),
('BE', 'BETA'),
('A', 'ALPHA'),
('D', 'DRAFT'),
('S', 'SUSPENDED'),
('U', 'UNKNOWN'),
('N', 'NOT SET'),
)
- Added
ownerattribute to scraper to assign scrapers to different owners when working on scrapers with various people (implemented as a simple/short plain text field to not endanger ex-/importability of scrapers) - New migrations
0020,0021please runpython manage.py migratecommand
Changes in version 0.12.3-beta (2017-06-09)
- Allowing
placeholderswith item attributes scraped from the main page inHEADERS,BODY,COOKIESfields andFORM DATAfor detail page URL requests - Fixing a bug causing log level setting on CL (with
-Lor--loglevel) not setting the correct log levels for different loggers - Using log level
WARNINGfor a condensed output format for many-items/pages scraper runs by adding structural information (“Starting to crawl item x.”, “Item x saved.”) to the log output - New spider method
struct_log(msg)used for logging structural information like above, if you want to include the “Item saved” log output in theWARNINGlog level output adopt your custompipelines.pyfile according to the one in the example project (see: Adding the pipeline class) - Added
DEBUGlog level output forplaceholderreplacements - Added additional logging output for calling detail page URLs and the additional request information (Headers, Body,…) sent
Changes in version 0.12.2-beta (2017-06-07)
- Added
use_default_procsattribute to scraper elems to allow switching of the usage of the default processors (Scrapy TakeFirst,DDS string_strip) (see: Default Processors), new migration0018, please runpython manage.py migratecommand - New
joinprocessor for convenience (see: Predefined Processors) analogue toJoinprocessor fromScrapy, has to be used with default processors deactivated - Official support for
Scrapy 1.4(no changes in the codebase though) - Declared
Python 3.4+support asstable - Closing DB connection when spider run is finished (GitHub issue #84)
- Set
LOG_STDOUTtoFalsein example project scraper settings due to a bug prevent scheduling from working when setting is activated (GitHub issue #80) - Also define an attribute update (STANDARD (UPDATE)) field as a successful action causing the scheduler to reset the zero actions counter and not increase time between scraper runs up to the max time (GitHub issue #88)
Changes in version 0.12.1-beta (2017-06-03)
- HOTFIX RELEASE! PLEASE UPDATE WHEN USING PYTHON 2.7!
- Fixed twisted logging filter, causing DDS completely refuse working under Python 2.7
Changes in version 0.12.0-beta (2017-05-12)
This release comes with a completely overhauled output formatting for scraper runs on the command line which should make it a lot easier to quickly grasp what your scrapers are doing and where things go wrong. Here is a sample output of a scraper run:
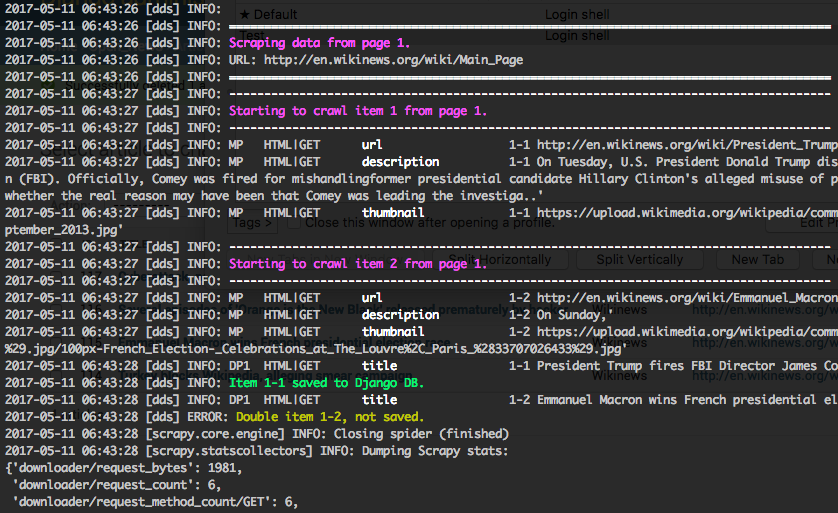
This is the output from the INFO log level (log level is taken from the
Scrapy LOG_LEVEL setting) which should in most cases now suffice for
normal scraper runs and debugging.
Some of the goodies:
- Formatted attribute output with extra info on attribute source (MP, DP) and request type
- Numbering of attributes by page, item number combination to easier track attributes belonging to one scraped object
- Colors for structuring the scraping output and indicate success/failure (works on both dark/light background terminals, dark theme is recommended though)
- Largely reducing the noise by supressing
twistedtraceroute output onINFOlog level
If you want item numbering and colors also in your “Item saved.” log output
messages you have to adopt your custom pipelines.py class (see: Adding the pipeline class,
adopt the spider.log command).
Note
There is still a known bug of the -L LOG_LEVEL setting from the command line
not properly taken in some cases, if you have problems here use the LOG_LEVEL
setting in your settings.py file.
There is now also an easier way to get help on the different command line options for scraper/checker runs and scraper test by typing the command without any options, e.g.:
scrapy crawl article_spider
Other changes:
- New
-a start_page=PAGEand-a end_page=PAGEoptions for setting a range of pages to scrape - Fixed a bug with
STANDARD (UPDATE)scraped object attributes - Replaced
DOUBLEkeyword-injecting (and bug causing?) workaround mechanism with_is_double metaattribute for scraped items
Changes in version 0.11.6-beta (2017-04-21)
- Fixed severe bug preventing scheduling to work with Python 3
Changes in version 0.11.5-beta (2017-04-20)
- Fixed broken management commands
check_last_checker_deletes,check_last_scraper_saves(see Monitoring Automation) andrun_checker_tests(see Run checker tests)
Changes in version 0.11.4-beta (2017-03-28)
- Added initial migrations for example project
- New optional argument
output_response_bodyfor checker run and checker test commands for easier checker debugging (see: Running your checkers and Run checker tests)
Changes in version 0.11.3-beta (2016-11-06)
- New processor
substr_replacefor replacing a substring occurring one or multiple times in the scraped element with a target string (see: Predefined Processors)
Changes in version 0.11.2-beta (2016-08-15)
- IMPORTANT BUG FIX RELEASE! Fixes a bug saving only one thumbnail size when several thumbnail sizes
are defined with
IMAGES_THUMBSsetting, bug was introduced with changes inDDS v.0.11.0
Changes in version 0.11.1-beta (2016-08-05)
- Easier way for writing/integrating Custom Processors for post-processing scraped data strings, new associated DSCRAPER_CUSTOM_PROCESSORS setting
Changes in version 0.11.0-beta (2016-05-13)
- First major release version with support for new
Scrapy 1.0+structure (onlyScrapy 1.1officially supported) - From this release on older Scrapy versions like
0.24are not supported any more, please update your Scrapy version! - Beta
Python 3support - Support for
Django 1.9 - The following manual adoptions in your project are necessary:
- Scrapy’s
DjangoItemclass has now moved fromscrapy.contrib.djangoitemto a separate repositoryscrapy-djangoitem( see Scrapy docs). The package has to be separately installed withpip install scrapy-djangoitemand the import in yourmodels.pyclass has to be changed tofrom scrapy_djangoitem import DjangoItem(see: Creating your Django models) - Due to Scrapy`s switch to Python`s build-in logging functionality the logging calls
in your custom pipeline class have to be slightly changed, removing the
from scrapy import logimport and changing thelog.[LOGLEVEL]attribute handover in the log function call tologging.[LOGLEVEL](see: Adding the pipeline class) - Change
except IntegrityError, e:toexcept IntegrityError as e:in your custompipelines.pymodule (see: Adding the pipeline class)
- Scrapy’s
- Following changes have been made:
- Changed logging to use Python’s build-in
loggingmodule - Updated import paths according to Scrapy release documentation
- Running most of the unit tests in parallel batches (when using the shell scripts) to speed up test runs
- Updated
django-celeryversion requirement to3.1.17to work withDjango 1.9 - Updated open_news example fixture, introduction of versioned fixture data dumps
- Removed dependency on
scrapy.xlib.pydispatchbeing removed inScrapy 1.1(formerDDS v.0.10releases will break withScrapy 1.1)
- Changed logging to use Python’s build-in
- If you use
Scrapy/SplashforJavascriptrendering:- Updated dependencies, replaced
scrapyjswithscrapy-splash(renaming), please update your dependencies accordingly!
- Updated dependencies, replaced
- Bugfixes:
- Fixed bug with
DSCRAPER_IMAGES_STORE_FORMATset toTHUMBSnot working correctly
- Fixed bug with
Changes in version 0.10.0-beta EXPERIMENTAL (2016-01-27)
- Experimental release branch no longer maintained, please see release notes for
0.11.
Changes in version 0.9.6-beta (2016-01-26)
- Fixed a severe bug causing scrapers to break when scraping unicode text
- Making unicode text scraping more robust
- Added several unit tests testing unicode string scraping/usage in various contexts
- Reduce size of textarea fields in scraper definitions
- Added order attribute for scraped object attributes for convenience when editing scrapers (see: Defining the object to be scraped)
- New migration
0017, run Djangomigratecommand
Changes in version 0.9.5-beta (2016-01-18)
- Fixed a severe bug when using non-saved detail page URLs in scrapers
Changes in version 0.9.4-beta (2016-01-15)
- Fixed a critical bug when using non-saved fields for scraping leading to incorrect data attribution to items
Changes in version 0.9.3-beta (2016-01-14)
- New command line options
output_num_mp_response_bodiesandoutput_num_dp_response_bodiesfor logging the complete response bodies of the first {Int} main/detail page responses to the screen for debugging (for the really hard cases :-)) (see: Running/Testing your scraper)
Changes in version 0.9.2-beta (2016-01-14)
- New processor
remove_chars(see: Processors) for removing one or several type of chars from a scraped string
Changes in version 0.9.1-beta (2016-01-13)
- Allowing empty
x_pathscraper attribute fields for easier appliance ofstaticprocessor to fill in static values - Enlargening
x_path,reg_expandprocessorfields in Django admin scraper definition fromCharFieldtoTextFieldfor more extensivex_path,reg_expandprocessordefinitions and more comfortable input/editing - New command line option
max_pages_readfor limiting the number of pages read on test runs (see: Running/Testing your scraper) - New migration
0016, run Djangomigratecommand
Changes in version 0.9.0-beta (2016-01-11)
- BREAKING!!! This release slighly changes the semantics of the internal
ValidationPipelineclass indynamic_scraper/pipelines.pyto also pass items to your custom user pipeline when thedo_actioncommand line parameter (see: Running/Testing your scraper) is not set. This creates the need of an additionalif spider.conf['DO_ACTION']:restriction in your custom user pipeline function (see: Adding the pipeline class). Make sure to add this line, otherwise you will get unwanted side effects. If you do more stuff in your custom pipeline class also have a broader look if this new behaviour changes your processing (you should be save though if you apply theifrestriction above to all of your code in the classs). - Decoupling of
DDSDjangoitem save mechanism for the pipeline processing to allow the usage of Scrapy`s build-in output options--output=FILEand--output-format=FORMATto scrape items into a file instead of the DB (see: Running/Testing your scraper). - The above is the main change, not touching too much code. Release number nevertheless jumped up a whole version number to indicate a major breaking change in using the library!
- Another reason for the new
0.9version number is the amount of new features being added throuhout minor0.8releases (more flexible checker concept, monitoring functionality, attribute placeholders) to point out the amount of changes since0.8.0.
Changes in version 0.8.13-beta (2016-01-07)
- Expanded detail page URL processor placeholder concept to generic attribute placeholders (Attribute Placeholders)
- Unit test for new functionality
Changes in version 0.8.12-beta (2016-01-06)
- Fixed
Clone ScraperDjango admin action omitting the creation ofRequestPageTypeandCheckerobjects introduced in the0.8series - Narrowing the requirements for
Pillowto3.xversions to reduce possible future side effects
Changes in version 0.8.11-beta (2016-01-05)
- New Attribute Placeholders (previously: detail page URL placeholder) which can be used for more flexible detail page URL creation
- Unit test for new functionality
Changes in version 0.8.10-beta (2015-12-04)
- New
--with-next-alertflag for monitoring management cmds to reduce amount of mail alerts, see updated Monitoring section for details - More verbose output for monitoring management cmds
- New migration
0015, run Djangomigratecommand
Changes in version 0.8.9-beta (2015-12-01)
- Minor changes
Changes in version 0.8.8-beta (2015-12-01)
- Fixed a bug in
Django adminfrom previous release
Changes in version 0.8.7-beta (2015-12-01)
- New syntax/semantics of management commands
check_last_checker_deletesandcheck_last_scraper_saves - Added
last_scraper_save_alert_periodandlast_checker_delete_alert_periodalert period fields for scraper, new migration0014, run Djangomigratecommand - New fields are used for providing time periods for the lowest accepted value for last scraper saves and checker deletes, these values are then checked by the management commands above (see: Monitoring)
- Older timestamps for current values of a scraper for
last_scraper_saveandlast_checker_deletealso trigger a visual warning indication in the Django admin scraper overview page
Changes in version 0.8.6-beta (2015-11-30)
- Two new management commands
check_last_checker_deletesandcheck_last_scraper_saveswhich can be run as a cron job for basic scraper/checker monitoring (see: Monitoring)
Changes in version 0.8.5-beta (2015-11-30)
- New
last_scraper_save,last_checker_deletedatetimeattributes forScrapermodel for monitoring/ statistis purposes (can be seen onScraperoverview page inDjango admin) - New migration
0013, run Djangomigratecommand
Changes in version 0.8.4-beta (2015-11-27)
Starting update process for Python 3 support with this release (not there yet!)
- Fixed severe bug in
task_utils.pypreventing checker scheduling to work - New dependency on Python-Future 0.15+ to support integrated
Python 2/3code base, please install withpip install future - Updating several files for being
Python 2/3compatible
Changes in version 0.8.3-beta (2015-10-01)
- More flexible checker concept now being an own
Checkermodel class and allowing for more than one checker for a single scraper. This allows checking for different URLs or xpath conditions. - Additional comment fields for
RequestPageTypesandCheckersin admin for own notes - Adopted unit tests to reflect new checker structure
self.scrape_url = self.ref_object.urlassignment in checker python class not used any more (see: Creating a checker class), you might directly want to remove this from your project class definition to avoid future confusion- Some docs rewriting for Checker creation (see: Defining/Running item checkers)
- New migrations
0011,0012, run Djangomigratecommand
Changes in version 0.8.2-beta (2015-09-24)
- Fixed bug preventing checker tests to work
- Added Javascript rendering to checkers
- Fixed a bug letting checkers/checker tests choose the wrong detail page URL for checking under certain circumstances
Changes in version 0.8.1-beta (2015-09-22)
- Fixed packaging problem not including custom static Django admin JS file (for
RequestPageTypeadmin form collapse/expand)
Changes in version 0.8.0-beta (2015-09-22)
- New request page types for main page and detail pages of scrapers (see: Adding corresponding request page types):
- Cleaner association of request options like content or request type to main or detail pages (see: Advanced Request Options)
- More flexibility in using different request options for main and detail pages (rendering Javascript on main but not on detail pages, different HTTP header or body values,…)
- Allowance of several detail page URLs per scraper
- Possibility for not saving the detail page URL used for scraping by unchecking corresponding new
ScrapedObjClassattributesave_to_db
- ATTENTION! This release comes with heavy internal changes regarding both DB structure and scraping logic. Unit tests are running through, but there might be untested edge cases. If you want to use the new functionality in a production environment please do this with extra care. You also might want to wait for 2-3 weeks after release and/or for a following 0.8.1 release (not sure if necessary yet). If you upgrade it is HIGHLY RECOMMENDED TO BACKUP YOUR PROJECT AND YOUR DB before!
- Replaced Scrapy
SpiderwithCrawlSpiderclass being the basis forDjangoBaseSpider, allowing for more flexibility when extending - Custom migration for automatically creating new
RequestPageTypeobjects for existing scrapers - Unit tests for new functionality
- Partly restructured documentation, separate Installation section
- Newly added
staticfiles, run Djangocollectstaticcommand (collaps/expand forRequestPageTypeinline admin form) - New migrations
0008,0009,0010, run Djangomigratecommand
Changes in version 0.7.3-beta (2015-08-10)
- New attribute
dont_filterforScraperrequest options (see: Advanced Request Options), necessary for some scenarios whereScrapyfalsely marks (and omits) requests as being duplicate (e.g. when scraping uniform URLs together with custom HTTP header pagination) - Fixed bug preventing processing of
JSONwith non-string data types (e.g.Number) for scraped attributes, values are now automatically converted toString - New migration
0007, run Djangomigratecommand
Changes in version 0.7.2-beta (2015-08-06)
- Added new
methodattribute toScrapernot binding HTTP method choice (GET/POST) so strictly to choice ofrequest_type(allowing e.g. more flexiblePOSTrequests), see: Advanced Request Options - Added new
bodyattribute toScraperallowing for sending custom requestHTTP message bodydata, see: Advanced Request Options - Allowing
paginationforheaders,bodyattributes - Allowing of
ScrapedObjectClassdefinitions inDjango adminwith no attributes defined asID field(omits double checking process when used) - New migration
0006, run Djangomigratecommand
Changes in version 0.7.1-beta (2015-08-03)
- Fixed severe bug preventing
paginationforcookiesandform_datato work properly - Added a new section in the docs for Advanced Request Options
- Unit tests for some scraper request option selections
Changes in version 0.7.0-beta (2015-07-31)
- Adding additional HTTP header attributes to scrapers in Django admin
- Cookie support for scrapers
- Passing Scraper specific Scrapy meta data
- Support for form requests, passing form data within requests
- Pagination support for cookies, form data
- New migration
0005, run Djangomigratecommand - All changes visible in Scraper form of Django admin
- ATTENTION! While unit tests for existing functionality all passing through, new functionality is not heavily tested yet due to problems in creating test scenarios. If you want to use the new functionality in a production environment please test with extra care. You also might want to wait for 2-3 weeks after release and/or for a following 0.7.1 release (not sure if necessary yet)
- Please report problems/bugs on GitHub.
Changes in version 0.6.0-beta (2015-07-14)
- Replaced implicit and static ID concept of mandatory
DETAIL_PAGE_URLtype attribute serving as ID with a more flexible concept of explicitly settingID FieldsforScrapedObjClassinDjangoadmin (see: Defining the object to be scraped) - New attribute
id_fieldforScrapedObjClass, please run Djangomigratecommand (migration0004) DETAIL_PAGE_URLtype attribute not necessary any more when defining the scraped object class allowing for more scraping use cases (classic and simple/flat datasets not referencing a certain detail page)- Single
DETAIL_PAGE_URLtypeID Fieldstill necessary for usingDDSchecker functionality (see: Defining/Running item checkers) - Additional form checks for
ScrapedObjClassdefinition inDjangoadmin
Changes in version 0.5.2-beta (2015-06-18)
- Two new processors
ts_to_dateandts_to_timeto extract local date/time from unix timestamp string (see: Processors)
Changes in version 0.5.1-beta (2015-06-17)
- Make sure that
Javascriptrendering is only activated for pages withHTMLcontent type
Changes in version 0.5.0-beta (2015-06-10)
- Support for creating
JSON/JSONPathscrapers for scrapingJSONencoded pages (see: Scraping JSON content) - Added new separate content type choice for detail pages and checkers (e.g. main page in
HTML, detail page inJSON) - New Scraper model attribute
detail_page_content_type, please run Djangomigrationcommand (migration0003) - New library dependency
python-jsonpath-rw 1.4+(see Requirements) - Updated unit tests to support/test
JSONscraping
Changes in version 0.4.2-beta (2015-06-05)
- Possibility to customize
Splashargs with new settingDSCRAPER_SPLASH_ARGS(see: Setting up Splash (Optional))
Changes in version 0.4.1-beta (2015-06-04)
- Support for
Javascriptrendering of scraped pages viaScrapyJS/Splash - Feature is optional and needs a working ScrapyJS/Splash deployment, see Requirements and Setting up Splash (Optional)
- New attribute
render_javascriptforScrapermodel, runpython manage.py migrate dynamic_scraperto apply (migration0002) - New unit tests for Javascript rendering (see: Running ScrapyJS/Splash JS rendering tests)
Changes in version 0.4.0-beta (2015-06-02)
- Support for
Django 1.7/1.8andScrapy 0.22/0.24. Earlier versions not supported any more from this release on, if you need another configuration have a look at theDDS 0.3.xbranch (new features won’t be back-ported though) (see Release Compatibility Table) - Switched to Django migrations, removed
Southdependency - Updated core library to work with
Django 1.7/1.8(Django 1.6and older not working any more) - Replaced deprecated calls logged when run under
Scrapy 0.24(Scrapy 0.20and older not working any more) - Things to consider when updating Scrapy: new
ITEM_PIPELINESdict format, standalonescrapydwith changedscrapy.cfgsettings and new deployment procedure (see: Scrapy Configuration) - Adopted
example_projectandtestsDjango projects to work with the updated dependecies - Updated
open_news.jsonexample project fixture - Changed
DDSstatus toBeta
Changes in version 0.3.14-alpha (2015-05-30)
- Pure documentation update release to get updated
Scrapy 0.20/0.22/.24compatibility info in the docs (see: Release Compatibility Table)
Changes in version 0.3.13-alpha (2015-05-29)
- Adopted test suite to pass through under
Scrapy 0.18(Tests don’t work withScrapy 0.16any more) - Added
Scrapy 0.18to release compatibility table (see: Release Compatibility Table)
Changes in version 0.3.12-alpha (2015-05-28)
- Added new release compatibility overview table to docs (see: Release Compatibility Table)
- Adopted
run_tests.shscript to run withDjango 1.6 - Tested
Django 1.5,Django 1.6for compatibility withDDS v.0.3.x - Updated title xpath in fixture for Wikinews example scraper
Changes in version 0.3.11-alpha (2015-04-20)
- Added
only-activeand--report-only-errosoptions torun_checker_testsmanagement command (see: Run checker tests)
Changes in version 0.3.10-alpha (2015-03-17)
- Added missing management command for checker functionality tests to distribution (see: Run checker tests)
Changes in version 0.3.9-alpha (2015-01-23)
- Added new setting
DSCRAPER_IMAGES_STORE_FORMATfor more flexibility with storing original and/or thumbnail images (see Scraping images/screenshots)
Changes in version 0.3.8-alpha (2014-10-14)
- Added ability for
durationprocessor to break down and parse second values greater than one hour in total (>= 3600 seconds) (see: Processors)
Changes in version 0.3.7-alpha (2014-03-20)
- Improved
run_checker_testsmanagement command with--send-admin-mailflag for usage of command in cronjob (see: Run checker tests)
Changes in version 0.3.6-alpha (2014-03-19)
- Added new admin action clone_scrapers to get a functional copy of scrapers easily
Changes in version 0.3.5-alpha (2013-11-02)
- Add super init method to call init method in Scrapy BaseSpider class to DjangoBaseSpider init method (see Pull Request #32)
Changes in version 0.3.4-alpha (2013-10-18)
- Fixed bug displaying wrong message in checker tests
- Removed
run_checker_testscelery task (which wasn’t working anyway) and replaced it with a simple Django management commandrun_checker_teststo run checker tests for all scrapers
Changes in version 0.3.3-alpha (2013-10-16)
- Making status list editable in Scraper admin overview page for easier status change for many scrapers at once
- Possibility to define
x_pathcheckers with blankchecker_x_path_result, the checker is then succeeding if elements are found on page (before this lead to an error message)
Changes in version 0.3.2-alpha (2013-09-28)
- Fixed the exception when scheduler string was processed (see Pull Request #27)
- Allowed Checker Reference URLs to be longer than the the default 200 characters (DB Migration
0004, see Pull Request #29) - Changed
__unicode__method forSchedulerRuntimeto preventTypeError(see Google Groups Discussion) - Refer to
IDinstead ofPK(see commit in nextlanding repo)
Changes in version 0.3.1-alpha (2013-09-03)
- Possibility to add keyword arguments to spider and checker task method to specify which reference objects to use for spider/checker runs (see: Defining your tasks)
Changes in version 0.3-alpha (2013-01-15)
- Main purpose of release is to upgrade to new libraries (Attention: some code changes necessary!)
Scrapy 0.16: TheDjangoItemclass used by DDS moved fromscrapy.contrib_exp.djangoitemtoscrapy.contrib.djangoitem. Please update your Django model class accordingly (see: Creating your Django models).Scrapy 0.16:BOT_VERSIONsetting no longer used in Scrapy/DDSsettings.pyfile (see: Setting up Scrapy)Scrapy 0.16: Some minor import changes for DDS to get rid of deprecated settings importDjango 1.5: Changed Django settings configuration, please update your Scrapy/DDSsettings.pyfile (see: Setting up Scrapy)django-celery 3.x: Simpler installation, updated docs accordingly (see: Installing/configuring django-celery for DDS)- New log output about which Django settings used when running a scraper
Changes in version 0.2-alpha (2012-06-22)
- Substantial API and DB layout changes compared to version 0.1
- Introduction of South for data migrations
Changes in version 0.1-pre-alpha (2011-12-20)
- Initial version
Roadmap¶
[THIS ROADMAP IS PARTIALLY OUTDATED!]
pre-alpha
Django Dynamic Scraper’s pre-alpha phase was meant to be for people interested having a first look at the library and give some feedback if things were making generally sense the way they were worked out/conceptionally designed or if a different approach on implementing some parts of the software would have made more sense.
alpha
DDS is currently in alpha stadium, which means that the library has proven itself in (at least) one production environment and can be (cautiously) used for production purposes. However being still very early in develpment, there are still API and DB changes for improving the lib in different ways. The alpha stadium will be used for getting most parts of the API relatively stable and eliminate the most urgent bugs/flaws from the software.
beta (current)
In the beta phase the API of the software should be relatively stable, though occasional changes will still be possible if necessary. The beta stadium should be the first period where it is save to use the software in production and beeing able to rely on its stability. Then the software should remain in beta for some time.
Version 1.0
Version 1.0 will be reached when the software has matured in the beta phase and when at least 10+ projects are using DDS productively for different purposes.